服务端开发者如何理解 AI Agent:从 ReAct 到 AgentOps
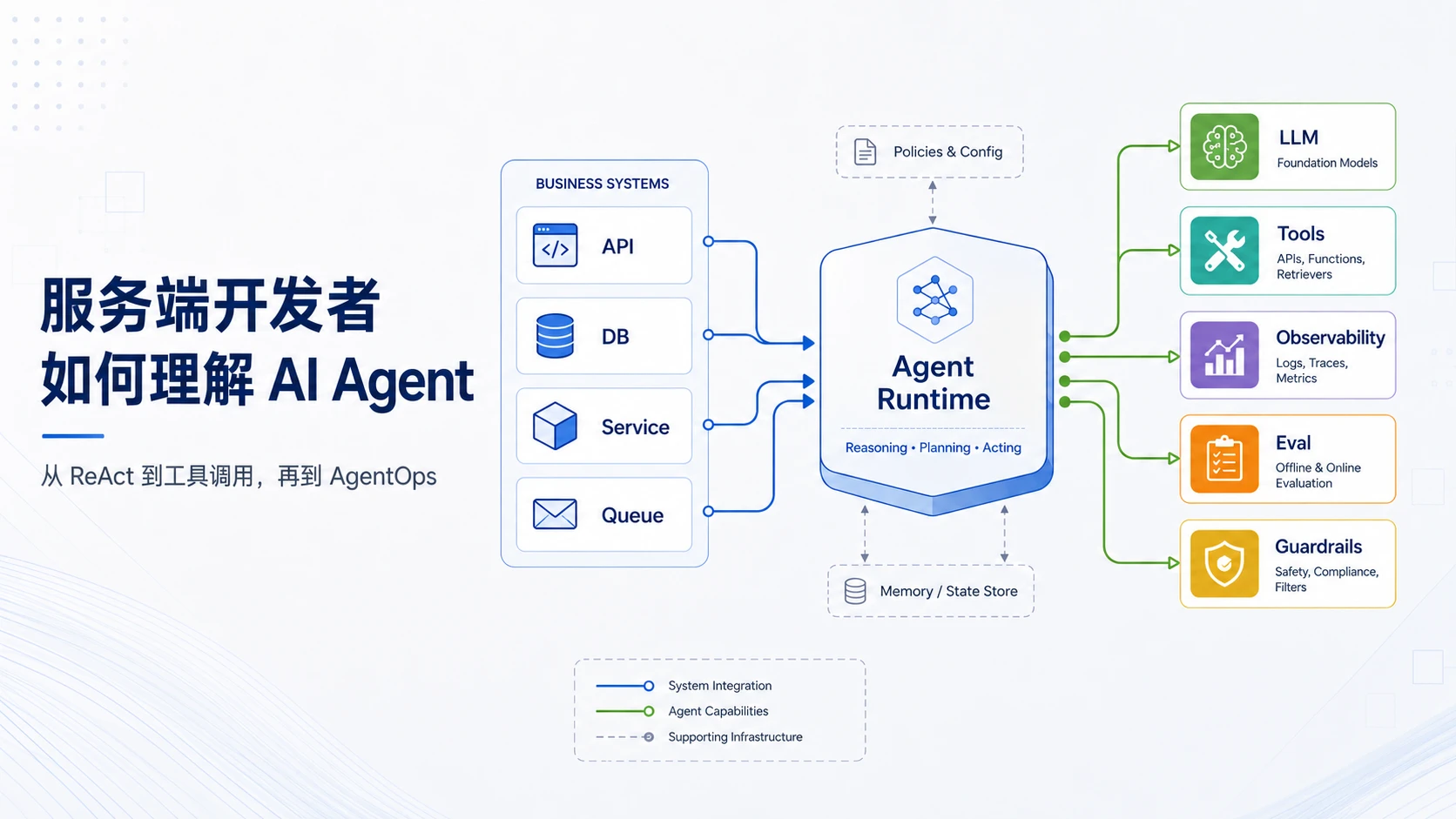
最近顺着 AI Agent 这条线做了一轮梳理。
起点是 ReAct 论文,后面一路看到了 CoT、Tool Calling、MCP、Skill、LangChain、LangGraph、多 Agent 架构,以及最近常被提到的 AgentOps。
这篇不是教程,也不是路线图,更像是一份面向服务端开发者的读书笔记。
我想回答的是一个更朴素的问题:
如果一个服务端开发者想理解 Agent 开发,大概可以从哪些概念开始看?这些概念和已有的工程经验之间,能不能建立一些对应关系?
看下来以后,我的感受是:Agent 开发里确实有很多新东西,但也没有完全脱离传统软件工程。
比如函数注册、协议设计、状态管理、异常处理、权限控制、日志追踪、服务治理,这些词换一个上下文,仍然能解释 Agent 系统里的很多问题。
区别在于,系统里多了一个会推理、会选择工具、但输出不完全稳定的组件。
这篇文章就沿着这个观察,把几个常见概念串起来。
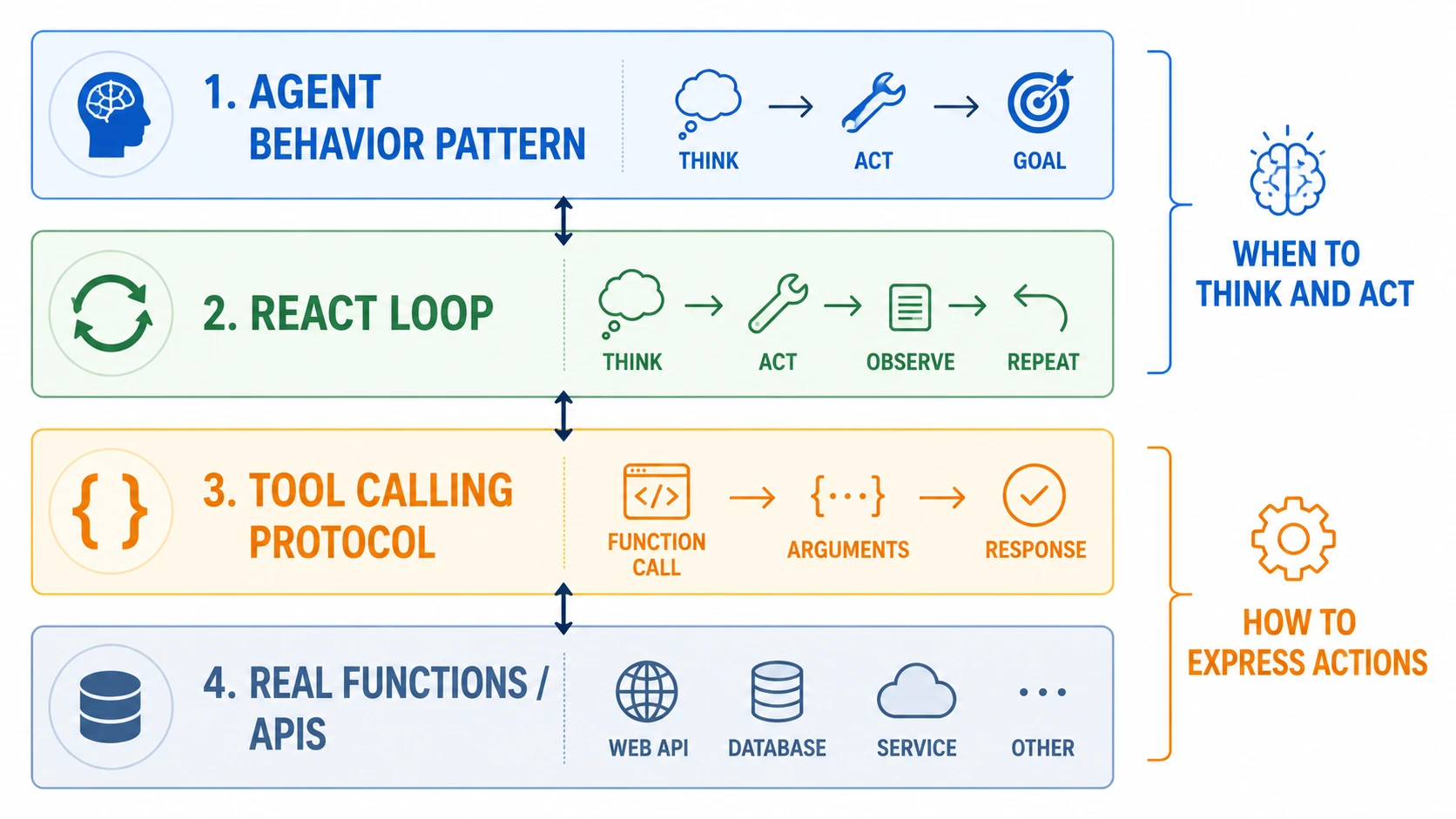
1. ReAct 不是前端 React
这里的 ReAct 不是前端框架 React,而是 Reason + Act。
它来自 LLM Agent 领域,核心思想是:不要让模型一次性回答问题,而是让模型在“思考、行动、观察、再思考”的闭环里解决问题。
一个典型的 ReAct 循环大概是:
1 | Thought: 我需要先查什么? |
它的关键价值不是代码多复杂,而是把 Agent 的基本工作循环标准化了:
1 | Thought -> Action -> Observation -> Thought -> ... -> Final Answer |
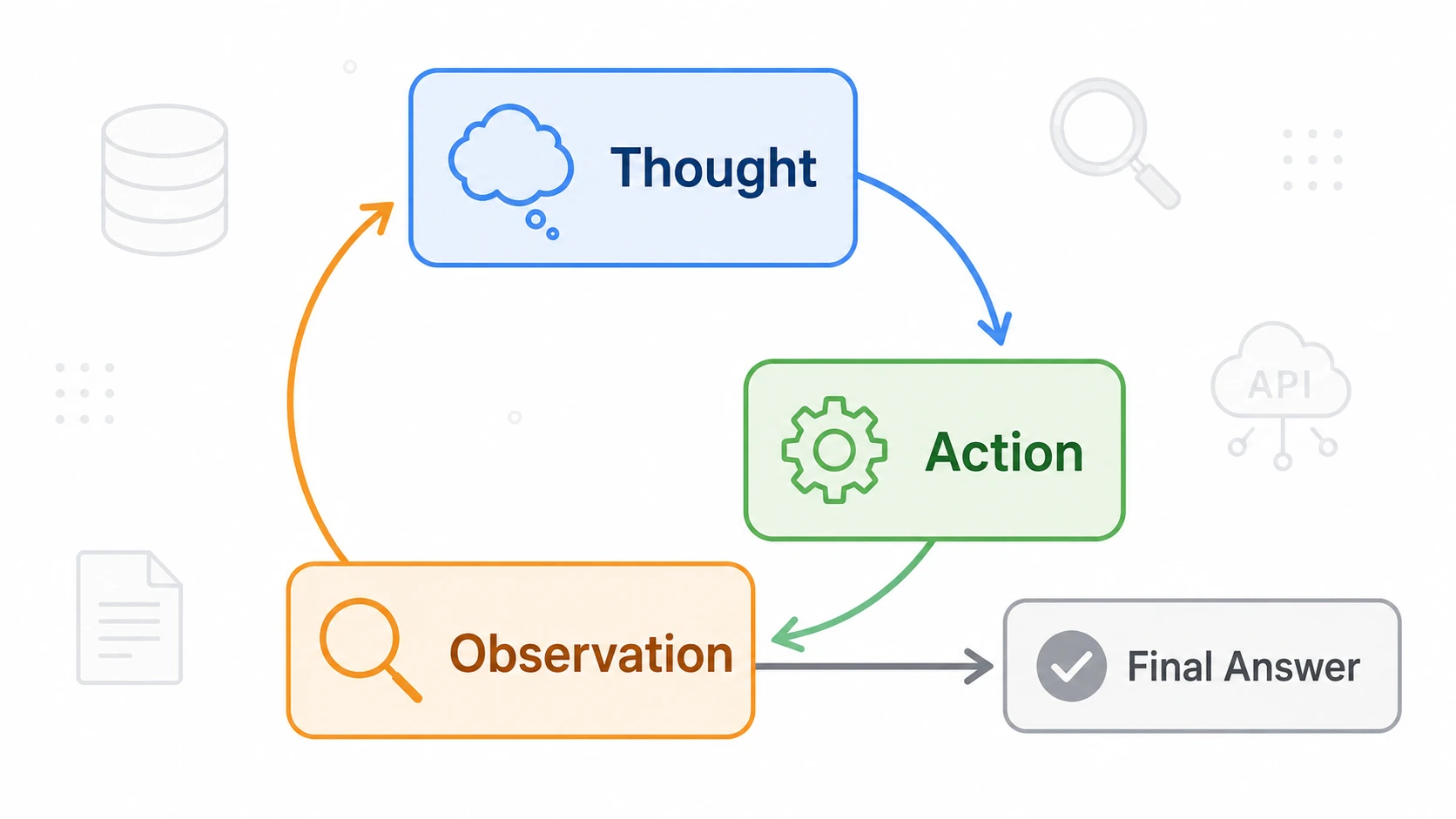
模型不再只是一次性生成文本,而是在外部环境反馈中逐步逼近答案。
论文里的几个实验场景也很典型。
HotpotQA 和 FEVER 偏知识推理、检索、事实验证。ALFWorld 和 WebShop 偏环境交互、决策、行动。
这说明 ReAct 想解决的不是“让模型回答得更像人”,而是让模型具备一种最小的行动闭环:先判断,再动作,拿到反馈后继续判断。
2. CoT 是想,ReAct 是边想边做
CoT,也就是 Chain-of-Thought,解决的是“让模型产生中间推理过程”的问题。
原始 CoT 是一种 prompting 技术:在 prompt 里给模型几个带推理过程的示例,让模型模仿这种推理格式。
后来 reasoning model 出现后,CoT 更像模型内部的计算过程。用户不一定能看到完整推理链,但模型会在内部做更多中间计算。
ReAct 和 CoT 的关系可以这样看:
1 | CoT: Thought -> Thought -> Thought -> Answer |
CoT 让模型想清楚。
ReAct 让模型边想边做,并把外部世界的反馈纳入下一步判断。
这一步很重要。
因为现实业务里的很多问题,不是靠模型“脑内想一想”就能解决的。它必须查数据库、调接口、看日志、读文档、比对状态、执行动作。
Agent 之所以成为 Agent,不是因为它会说话,而是因为它能在一个受控环境里行动。
3. Agent 调工具,可以拆成普通调用链路
第一次看到 Agent 调工具,很多人会觉得神奇:
模型怎么知道要调用哪个函数?
又怎么知道参数应该怎么传?
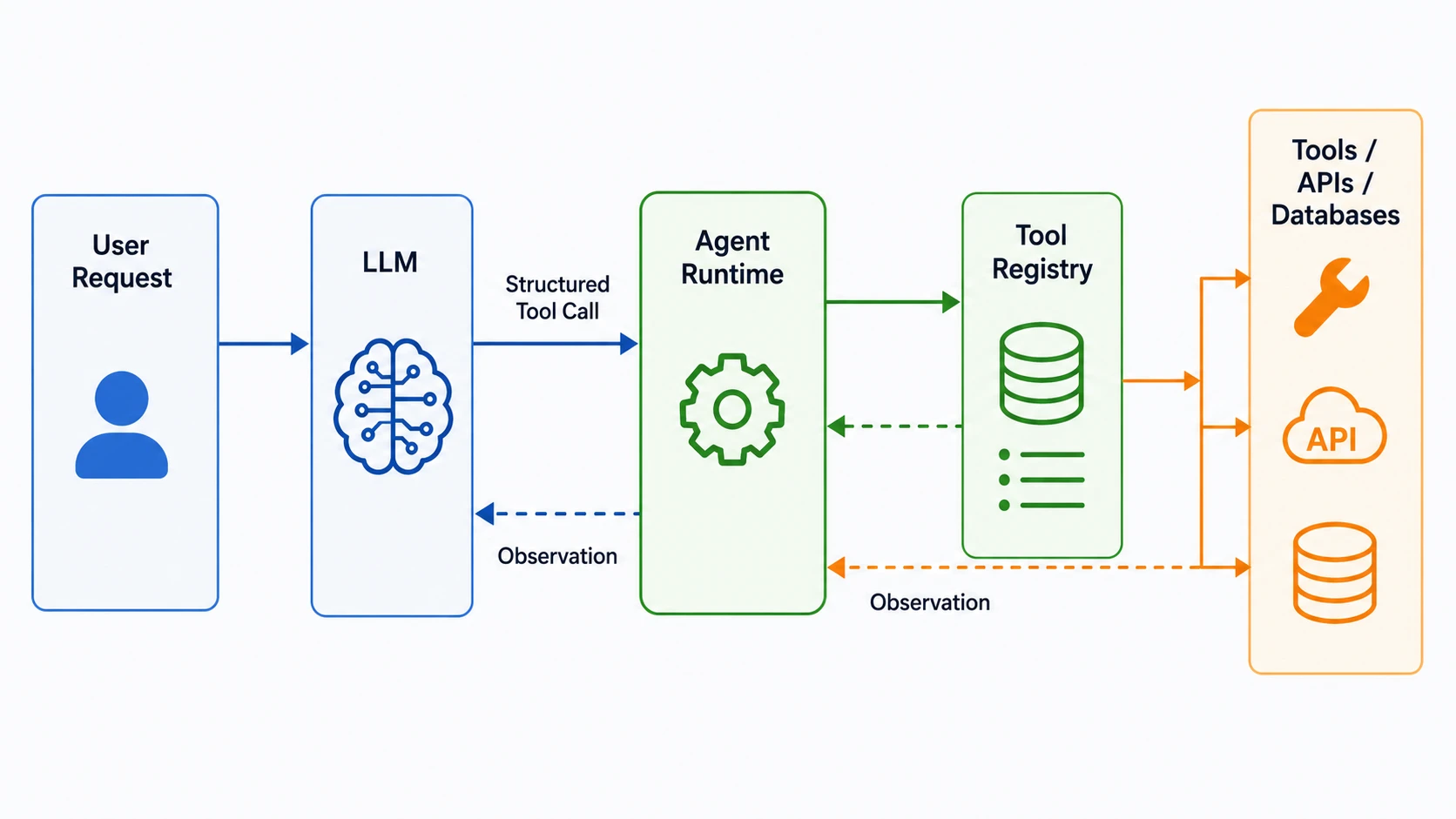
但从服务端视角拆开看,它仍然是一条可以理解的调用链路。
模型本身不会真正执行工具。它只是根据你提供的工具描述和参数 schema,生成一个结构化意图:
1 | 我要调用 query_order |
实际执行函数的是 Agent Runtime,也就是你的代码或框架。
完整链路大概是:
1 | 用户问题 |
伪代码也很直观:
1 | while True: |
所以,一个最小 Agent Runtime 本质上就是几件事:
- 函数注册表
- 工具描述
- Tool Call 解析器
- 调用执行器
- 上下文维护器
模型负责判断“下一步该调用什么”。
代码负责执行真实动作。
这就是 Agent 调工具的本质。
4. Function Calling 解决的是协议稳定性
早期 ReAct 常见的是文本协议:
1 | Action: query_order |
这种方式能跑,但有一个问题:不稳定。
模型可能多写一句解释,可能少写一个字段,可能输出不合法 JSON。只要格式漂移,解析器就会出问题。
Function Calling / Tool Calling 做的事情,是把这一步升级成模型 API 原生支持的结构化协议。
开发者用 JSON Schema 描述工具,模型返回结构化 tool call,而不是随便写一段文本。
它的核心价值不是让模型真的调用函数。
模型仍然不执行函数。真正执行函数的仍然是 Runtime。
Function Calling 的价值在于,让模型用稳定、机器可读、schema 约束的方式表达:
1 | 我现在要调用哪个工具,以及参数是什么。 |
所以 ReAct 和 Function Calling 不是替代关系。
它们解决的是两个层面的问题:
- ReAct 解决“什么时候思考,什么时候行动”
- Function Calling 解决“行动指令如何稳定表达”
一个是推理-行动范式,一个是工具调用接口协议。
5. LangChain、LangGraph 和多 Agent
如果只是手写一个最小 ReAct Agent,100 到 200 行 Python 就能跑起来。
但一旦进入试生产,真正消耗时间的通常不是 agent loop,而是这些问题:
- 工具粒度怎么设计
- 工具 schema 怎么定义
- Observation 怎么压缩
- 失败后怎么重试
- 执行多少步应该停止
- 哪些操作需要人工确认
- 每次运行怎么记录 trace
- 如何构建评测集
这也是 LangChain 和 LangGraph 的价值所在。
LangChain 更像 AI 应用工具箱,提供模型集成、Prompt Template、Tool、Retriever、Memory、Output Parser 等组件。
LangGraph 更像有状态图执行引擎,适合复杂流程、多 Agent 协作、条件分支、循环推理、人工审批、中断恢复和长任务。
一句话概括:
1 | LangChain 提供组件。 |
至于多 Agent,不应该一开始就上。
更稳妥的演进路线是:
1 | 单 Agent + 多 Tools |
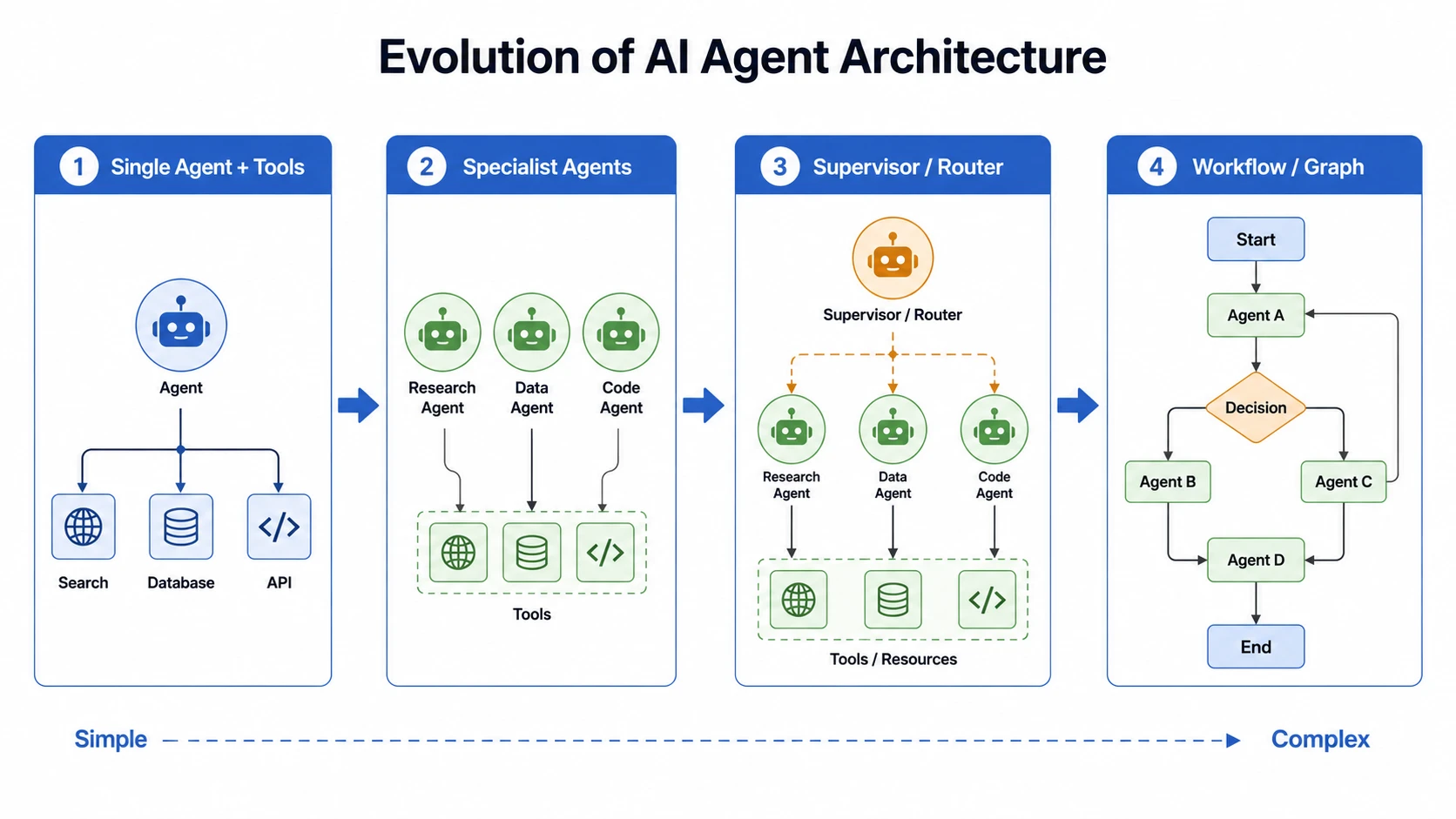
Tool 是能力原子。
Agent 是任务专家。
Supervisor 是任务调度器。
Workflow 是确定性流程。
服务端开发者应该很熟悉这个判断:不是所有逻辑都应该拆成微服务,也不是所有流程都应该交给模型动态决策。
稳定、高频、规则明确的流程,更适合 workflow。
开放、不稳定、需要判断的问题,才适合交给 Agent。
6. Tool、MCP、Skill 怎么理解
这几个概念也很容易混在一起。
可以这样区分:
- Tool:Agent 运行时可调用的函数、API 或动作
- MCP:把外部工具、资源、Prompt 标准化暴露给 Agent 的协议
- Skill:把某类任务的方法论、流程、规范、资源和脚本打包成能力包
一个粗略类比:
1 | Tool 是可执行函数。 |
所以 Skill 不一定等于 Tool。
一个 Skill 可能只是告诉 Agent 应该按什么流程做事,也可能附带脚本、模板和资源。
对工程师来说,可以把 Tool 看作函数,把 MCP 看作标准化接口层,把 Skill 看作可复用的任务上下文包。
7. 从服务端开发视角看,需要补哪些拼图
如果从服务端开发的视角看 Agent 开发,有一部分能力是可以迁移的。
比如:
- API 设计
- 异步任务
- 状态管理
- 权限控制
- 日志追踪
- 错误处理
- 数据建模
- 服务治理
- 工程部署
但也有一些新问题需要单独补课。
我目前看到的主要是这些:
- 怎么把业务任务拆成 Agent 可以执行的结构
- 怎么设计稳定的 Tool schema
- 怎么控制上下文和 Observation
- 怎么建设 eval set
- 怎么记录 trace,并用 trace 调试行为
- 怎么判断哪些流程该 workflow 化,哪些可以交给 Agent 判断
- 怎么设计权限、审批、幂等和回滚
- 怎么控制成本、延迟和模型 fallback
这些问题不一定都要在第一天解决。
但如果一个 Agent 真要进入业务系统,它们迟早会出现。
这也是我觉得服务端开发经验有用的地方。
服务端工程本来就经常要处理不稳定的外部依赖、复杂的业务状态和不可控的用户输入。
只不过这一次,被接入系统的外部能力变成了 LLM 和一组可被模型选择的工具。
8. AgentOps:我目前看到的生产化问题
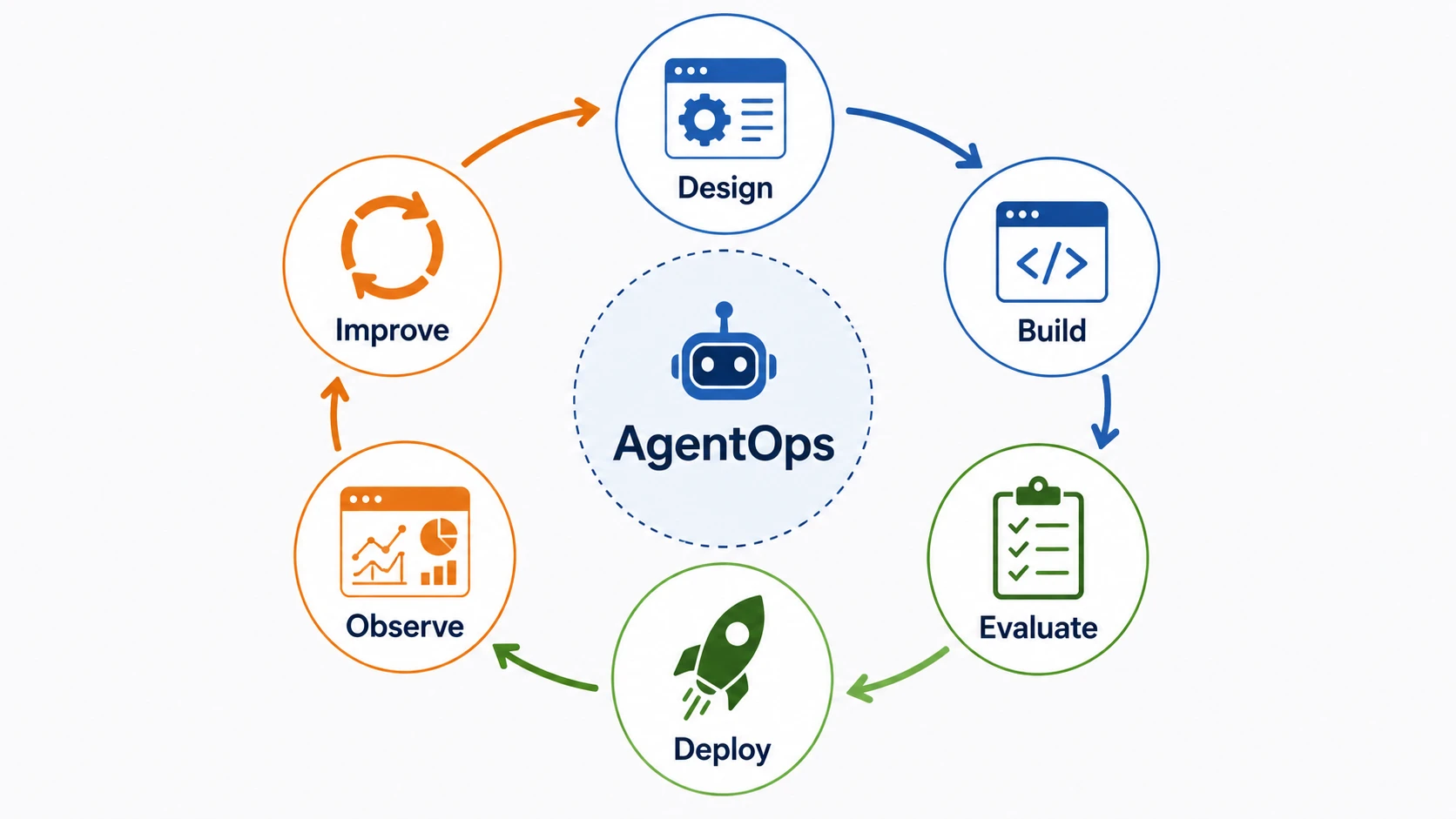
看 Agent 系统的生产化讨论时,经常会遇到 AgentOps 这个词。
它还没有像 DevOps、MLOps 那样完全标准化。我的理解是,它现在更像一组正在成型的工程实践。
当 Agent 不只是回答问题,而是开始检索数据、调用工具、执行动作、影响业务系统时,你就不能再把它当成一个普通接口。
你需要知道它每一步做了什么,为什么这么做,调用了什么工具,花了多少钱,哪里失败了,能不能回滚,下次怎么避免同类错误。
所以我会先把 AgentOps 理解成:
面向生产 Agent 的运行、观测、评测和治理能力。
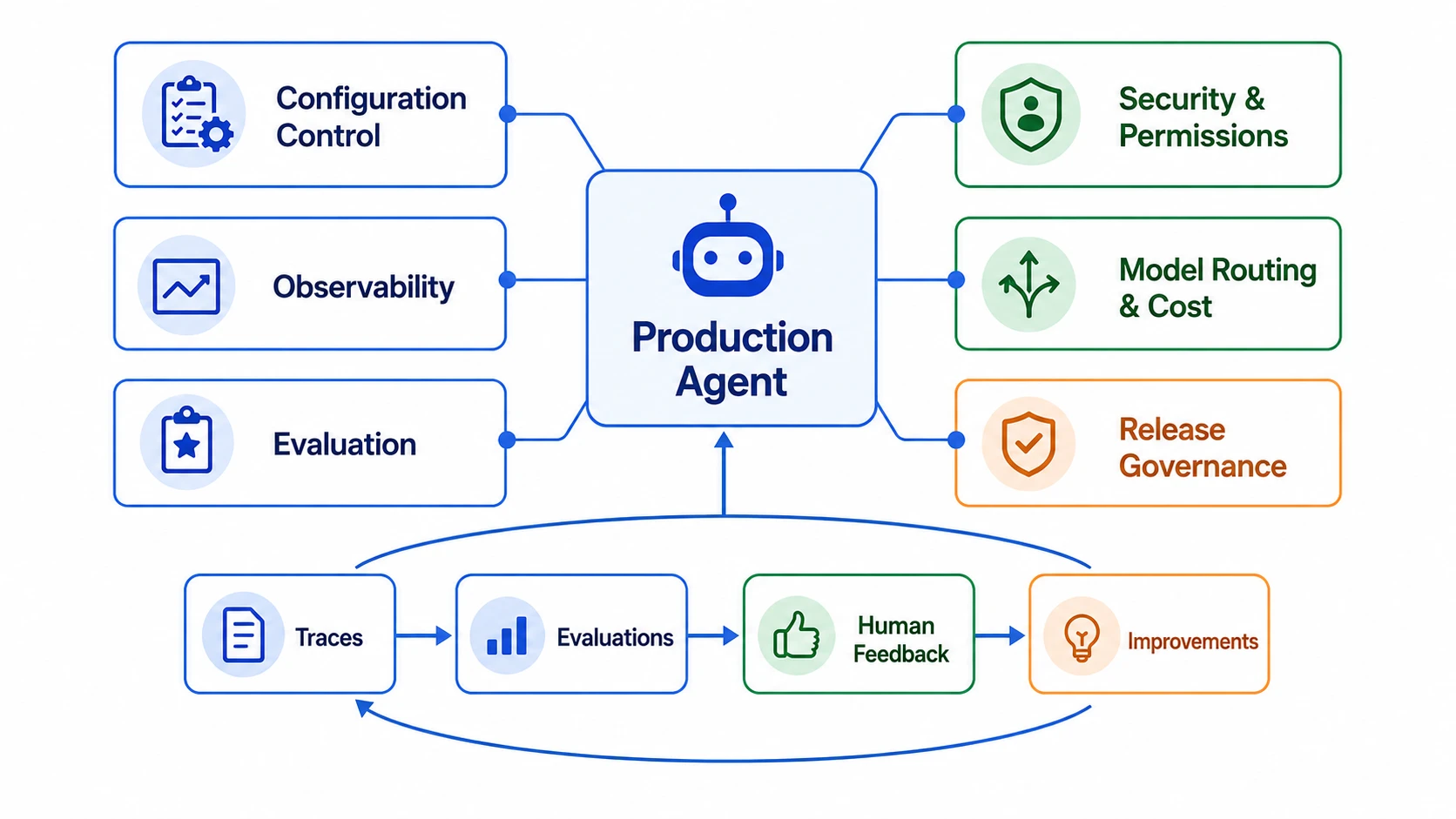
它不是单个工具,也不是简单的日志平台,而是一组围绕 Agent 生命周期的工程能力。
第一层是配置控制。
Prompt、Tool、Skill、模型选择、路由策略、权限策略,都不应该散落在代码里。
它们应该可配置、可版本化、可灰度、可回滚。
否则每一次改 prompt、改工具描述、换模型、调路由规则,都要重新发版,迭代会非常重。
第二层是运行观测。
传统服务只看日志、指标、链路追踪还不够。
Agent 需要的是 Agent Observability。
一次完整运行里,至少要记录这些东西:
- 用户输入
- 被选中的 prompt 和版本
- 模型请求和响应
- 每一次工具调用
- 工具入参和返回
- Observation 如何进入上下文
- 中间状态如何变化
- 最终输出
- 人工修正
- 业务结果
- token、成本、延迟和错误
普通日志只能告诉你“系统有没有报错”。
Agent trace 要回答的是:“这个 Agent 为什么会这样做”。
第三层是评测体系。
没有 eval,就没有 Agent 迭代。
因为 Agent 的失败经常不是代码异常,而是“看起来成功,实际上做错了”。
比如工具调用成功了,但选错了工具;回答生成了,但漏掉关键约束;流程跑完了,但业务结果不合格。
这类问题不能只靠线上反馈,也不能靠人工偶尔看几条日志。
你需要把真实任务沉淀成 golden tasks,把失败案例沉淀成 regression set。每次改 prompt、换模型、改 tool schema、调整 workflow,都要跑一遍评测。
对 Agent 来说,eval 就是 CI。
第四层是发布治理。
传统代码发布有灰度、回滚、监控、告警。
Agent 也需要类似机制,而且要更细。
因为 Agent 的变化不只来自代码,还来自 prompt、模型版本、工具返回、知识库内容、上下文策略和路由策略。
成熟一点的发布流程应该包括:
- shadow test:先旁路运行,不影响真实结果
- canary:只放给小比例流量
- A/B test:比较不同 prompt、模型或 workflow
- rollback:质量下降时快速切回上一版本
- freeze:出现风险时冻结高危工具或写操作
- human approval:敏感动作必须人工确认
第五层是权限和安全。
Agent 一旦能调用工具,就不只是“生成文本的模型”。
它变成了一个有行动能力的系统参与者。
所以工具权限必须最小化,写操作必须受控,高危动作必须审批,敏感数据必须脱敏,所有关键动作必须可审计。
这部分不能靠 prompt 里的“请你谨慎操作”解决。
它应该由系统权限、工具网关、审批流和审计日志来保证。
第六层是多模型和成本控制。
生产里的模型供应商、价格、延迟、稳定性都会变化。
成熟系统最好抽象出 Model Gateway / Model Router,支持 primary model、fallback model、timeout fallback、error fallback、cost-based routing、task-based routing、A/B test、shadow test 和灰度切换。
不是所有任务都需要最强模型。
简单分类、格式转换、信息抽取,可以走便宜模型;复杂推理、关键决策、长上下文分析,再走更强模型。
这不是省钱小技巧,而是生产系统的稳定性设计。
所以我不太把 AgentOps 当成一个新名词看。
它更像是在提醒我们:Agent 不是一次性交付的功能,而是一套需要持续观察、评估、约束、回滚和迭代的概率系统。
如果说 ReAct 解决的是 Agent 的最小行动闭环,那么 AgentOps 关注的是 Agent 进入生产之后的长期运行问题。
9. 总结
如果用工程师能理解的话说,Agent 不一定要被理解成一个全新的工程门类。
它更像是在传统业务系统里接入了一个会推理、会选择工具、但输出不完全稳定的决策组件。
围绕这个组件,服务端开发者可以先关注这些问题:
- 用 Tool schema 约束动作
- 用 Runtime 执行真实函数
- 用 Workflow 固化稳定流程
- 用 Trace 记录运行过程
- 用 Eval 衡量效果
- 用权限和审批控制风险
- 用 fallback 管住成本和稳定性
这也是我目前理解 AI Agent 开发的一条线索:
先理解 ReAct 的思考-行动闭环,再理解工具调用的运行时机制,最后把它落到工程系统的稳定性、可控性和可持续迭代能力上。